RAG vs LLMs: How to Choose the Right AI Model for Your Business

Navigating the AI Landscape: Why Now Is the Time to Decide Between RAG and LLMs
Can your AI system tell the difference between old news and breaking news? Can it pull insights from your own documents instead of relying solely on what it “remembers”? For many tech teams, choosing between Retrieval-Augmented Generation (RAG) and traditional Large Language Models (LLMs) isn’t just about performance, it’s also about relevance, accuracy, and cost-efficiency.
Let’s break down the real differences between RAGs and LLMs, pinpoint where RAG clearly wins, and help you decide what’s best for your enterprise applications.
What Is a Traditional LLM?
Before we start comparing the two, let’s understand what traditional large language models bring to the table and where they fall short.
Memory-Based Power with Limits
Traditional LLMs, like ChatGPT or Gemini, operate purely on their training data. Once trained, they become static. That means:
- They can’t learn new information unless retrained.
- They generate answers based solely on internal memory.
- Their knowledge is only as current as their last update.
LLM Strengths:
- Excellent at generating coherent language.
- Great for storytelling, creative writing, and general queries.
LLM Weaknesses:
- Susceptible to hallucinations. LLMs can confidently generate false or outdated information, often drifting from the original prompt. This remains their biggest flaw.
- Outdated when it comes to recent events.
- Not tailored to your organization’s specific data.
Thinking about integrating AI into your workflow? EspioLabs can help you choose the right model foundation to enhance your operational flow.
What Is RAG (Retrieval-Augmented Generation)?
Now that we know how traditional LLMs operate, let’s explore how RAG models offer a different approach by integrating real-time data retrieval.
RAG models combine the power of traditional LLMs with a live data retrieval system. In short: RAGs can use datasets to looks things up, while LLMs rely solely on memory.
How a RAG works:
- A retriever pulls relevant information from external sources (like databases, internal documents, or web content).
- The generator (LLM) uses that retrieved data to produce context-rich answers. The strength of the answers is highly dependent on the information given and will greatly impact the performance of your LLM.
Why it matters:
- RAG allows your model to stay current without retraining every time new information gets released.
- You can inject your own company data to get tailored responses to your business operations and procedures.
Want answers based on your proprietary documents, and not just from the internet? EspioLabs builds custom RAG pipelines for secure enterprise use, accelerating decision-making, productivity, and access to critical insight.
Core Differences Between RAG and Traditional LLMs
This section compares both technologies across critical performance areas helping you understand where RAG fills the gaps left by traditional LLMs.
| Feature | Traditional LLM | RAG Model |
| Data Freshness | Static, outdated | Live, real-time retrieval |
| Context Handling | Internal memory only | Dynamic context from sources |
| Accuracy | Prone to hallucination | Factual, source-grounded output |
| Customization | Requires fine-tuning | Index content for real-time use |
| Security Control | Limited | Full source and access control |
Curious how these features translate into business outcomes? Our AI consultants in Ottawa can help you make the right pick for your business.
RAG Use Cases
Let’s look at specific scenarios where RAG shines compared to traditional LLMs, particularly in real-world business and technical applications.
Retrieval-Augmented Generation shouldn’t be used for everything, but it shines in domains where accuracy, recency, and control matter.
- Customer Support
- Pulls answers from real-time knowledge bases and updated policies.
- Legal & Compliance
- Surfaces precise citations and documents.
- Technical Documentation
- Accesses the latest code libraries or internal API specs.
- Enterprise Search
- Allows employees to ask questions and receive answers instantaneously from company documents, with very high accuracy.
- Fact-Driven Publishing
- Great for newsrooms and editorial teams that require the latest figures.
Want to see what a RAG-enabled chatbot would look like for your support team? EspioLabs can prototype one for you. Contact our AI specialists in Ottawa to learn more.
RAG vs LLM Performance: Detailed Comparison
In this section, we zoom in on three high-impact areas: data retrieval, output accuracy, and fine-tuning flexibility.
Retrieving Current Data
- LLM: Knowledge capped at training date.
- RAG: Can ingest and reference new data regularly.
Accuracy and Hallucinations
- LLM: May fabricate statistics or quotes.
- RAG: Answers backed by real-world documents and data.
Fine-Tuning vs Retrieval
- LLM: Needs full retraining for domain adaptation.
- RAG: Just index new content—no retraining needed.
RAG vs LLM Cost and Enterprise AI Model Considerations
What should your IT team consider before investing? Here’s how RAG stacks up when it comes to total cost of ownership and operational flexibility.
Cost Efficiency
- RAG reduces infrastructure and retraining costs.
- Smaller base models + smart retrieval = better ROI.
Customization
- Easily integrate internal data sources.
- No need for expensive custom LLM training every time your policy changes.
Security and Compliance
- RAG allows for access-controlled retrieval.
- Keeps confidential information internal, while still usable by the model.
Need to meet strict compliance standards with AI? Get in touch to learn how EspioLabs helps you deploy RAG systems that pass compliance checks and audits.
Real-World Results: RAG in Action
Still not convinced? These example use cases show how organizations like yours are already using RAGs to drive better results and more trustworthy AI outputs.
1. Legal Case Research
Reduced hallucination rate when searching legislation.
AI tools connected to trusted legal databases help avoid incorrect references. This leads to more accurate case law analysis and fewer misquoted statutes.
2. Customer Service Knowledge Bases
Support bots improved first-contact resolution.
RAGs integrated with company-specific data can answer complex questions faster. Customers get relevant answers without waiting for human escalation.
3. Pharma Research Teams
Able to access newly published trials missed by LLMs.
Search tools with live data access can surface the latest medical studies. This helps researchers stay ahead without relying on outdated model training.
Want to implement a RAG within your own org? EspioLabs offers tailored AI deployments.
Decision Guide: When to Use RAG or LLM
Trying to decide which model fits your use case? This framework gives you a side-by-side view for fast, confident choices.
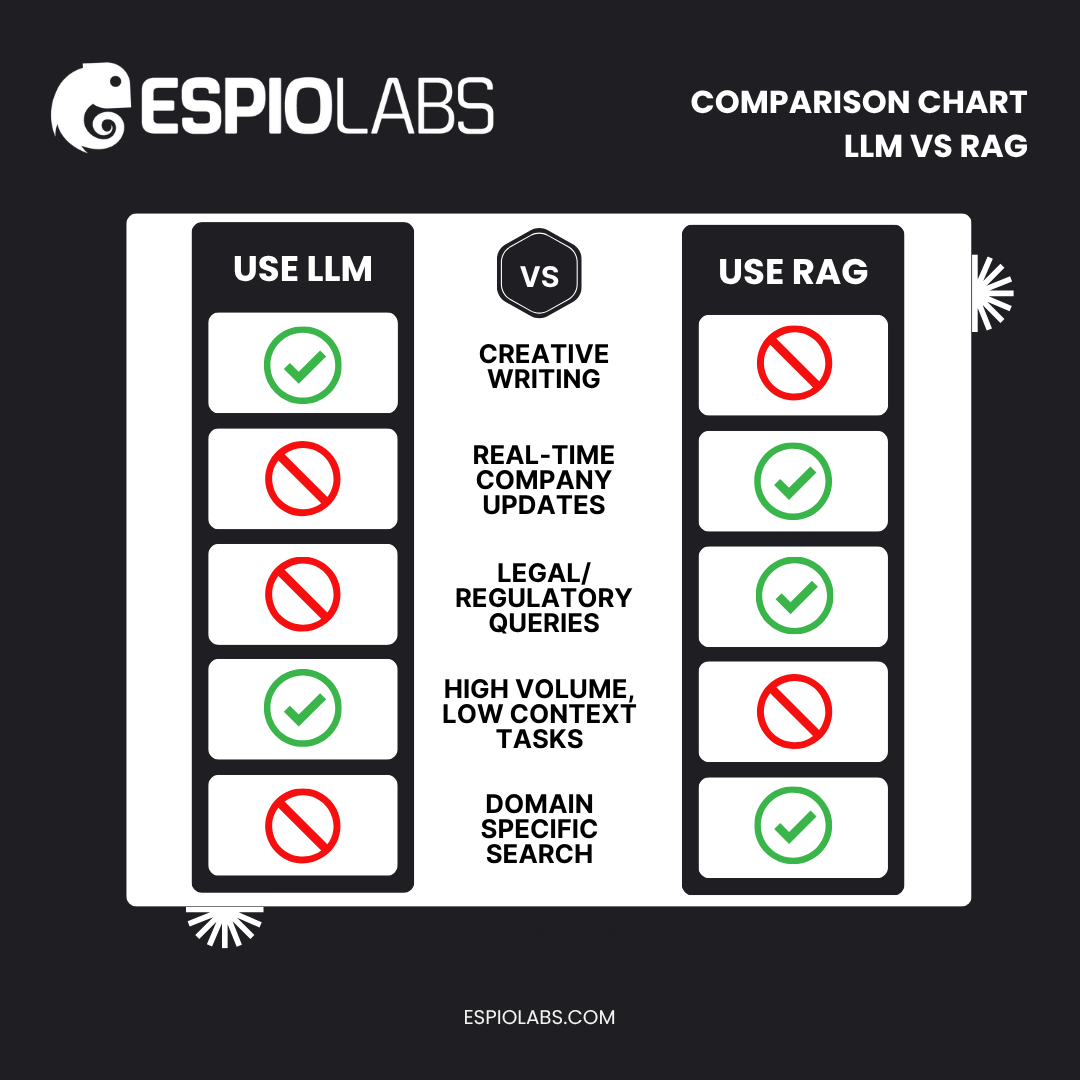
Final Thoughts: Choose AI That Grows With You
RAG empowers your team to tap into memory and real-time truth. That means better decisions, lower costs, and more confidence in your outputs. Connect with EspioLabs to deploy your own RAG-powered future.
Related Reads:
The Future of LLMs and Why Strategic Adoption Can’t Wait
What Is RAG in Generative AI? How Retrieval-Augmented Generation Solves Hallucination
Foundation Models in LLMs: What They Are and Why They Matter



